超过现有最先进模型!网易云音乐2篇论文入选ICASSP2023
|
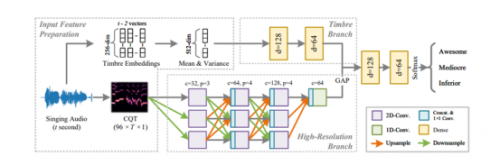
近日,网易云音乐2篇论文《TG-Critic: A Timbre-Guided Model for Reference-Independent Singing evaluation》《TrOMR:Transformer-based Polyphonic Optical Music Recognition》入选ICASSP2023,论文提出的两种算法模型均优于现有最先进模型。 一种是歌唱评价算法模型TG-Critic,利用它可以仅依靠一段演唱音频判断歌手演唱水平,实验结果表明,算法模型评估的歌曲与人工专家评价“演唱水平好”的歌曲,相似度达91%;另一种是识别图像乐谱的算法模型,通过模型识别图片中的五线谱,实验结果在复音乐谱上的错误率最高也仅为2.1%。 据了解,ICASSP(International Conference on Acoustics, Speech and Signal Processing)即国际声学、语音与信号处理会议,是IEEE主办的全世界最大的,也是最全面的信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。此次入选,代表了网易云音乐在国际舞台上,展示出了在音乐音频领域的技术实力。 而且凭借在音乐技术领域的积累创新,网易云音乐也不断将前沿领域研究成果应用于实践。依靠目前准确率最高的歌曲质量评价算法,歌唱评价将不再依赖人力手工准备模板物料,歌手也不再需要模仿模板以获取高分,更鼓励歌手的个性化演绎。而且相比卡拉ok中的传统歌唱评价,该模型未来将用于更加丰富的使用场景,如歌曲分发、优质歌手挖掘、声音社交等等领域。而利用识别图像乐谱的算法模型,可以将模糊的图片乐谱准确识别,方便转换为利用率更高的格式,服务于音乐人、用户在欣赏、教育、创作等场景的需要。 三大技术创新拆解“开口跪”,将全球最优算法准确率至少提升4% 当歌唱老师和专家听到一首歌,就能迅速可以判断出歌手的演唱水平,而普通人则会用“开口跪”表达夸赞。当人们评价歌声质量时,人声的音色是影响判断的重要因素。受其启发,网易云音乐首创提出了一个音色为指导的歌唱评价模型:TG-Critic,将全球最优算法准确率提升4%以上。 据介绍,网易云音乐音频实验室在歌唱评价模型的设计过程中引入了三个主要创新点: 1.首次在模型中显式引入音色信息辅助歌声评价:研究表明,歌手的"音色"是影响人们对于歌声感受的重要因素。但不同于音准、节奏等较为简单的属性,音色是一系列复杂而抽象的感受的集合,因此其提取过程更为复杂,更难被模型直接捕捉到。至今为止的歌声自动评价系统中,还没有研究聚焦音色特征对于模型预测的影响。 为了填补这一空缺,团队创新性地使用原本为“歌手识别”任务设计的预训练模型,提取与音色相关的高级特征,并将其用作歌声评价模型的输入。尽管这些特征原本并非为歌声质量设计,但是来自质量标签为“好”和“差”的样本的特征,在高维空间中分别呈现出较明显的聚集现象,证明了其与歌声质量的相关性。
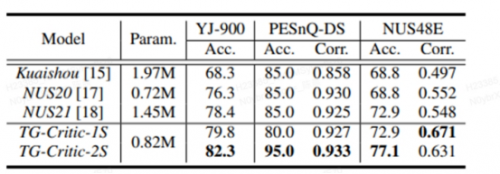
2.迁移高分辨率网络结构处理声谱特征:除了音色特征输入,团队从音频样本中提取CQT声谱特征作为模型的主要输入。为了解决卷积网络局部性带来的问题,团队将图像分割领域较为常用的“高分辨率网络”迁移到歌声评价任务中,分别通过高、中、低三个不同的分辨率分支分别处理特征。通过高分辨率特征捕捉局部信息(如演唱技巧、小瑕疵等)、低分辨率特征捕捉长距离信息(气息稳定性、音准等),从而实现保持高效性的同时,提升模型提取有用信息的能力。 3.提出循环自动数据标注降低人工成本: 对于一个模型的训练,可靠的标注数据尤为重要。团队收集了3万余条歌声数据样本,以及其对应的机器打分(针对音准、节奏等)、红心数、评论数等可以一定程度反映歌声质量的元数据。通过一个循环迭代过程,只需要人工标注其中小部分样本,便能获得足够可靠的自动数据标签,大大降低了标注所需的人工成本。 实验结果表明,在各类公开数据集上,网易云音乐提出的TG-Critic均达到国际最先进水平,相比已有算法,准确率提升至少4%,部分数据集提升10%以上。而且应用于网易云音乐业务测听的结果显示:在音乐人业务:运营评估歌曲推荐值≥3共159首歌曲中,算法评价为“演唱水平好”共144首,准确率达90.5%;在直播业务:运营提供100首算法判定“演唱水平好”歌曲的人工验证,准确率91%;在500+全演唱水平分类实验中,准确率81.2%。
据了解,TG-Critic歌曲质量评价模型将进一步减少人力依赖并扩大应用场景在直播、音乐人等内容分发场景,可协助人工挑选优质内容,可服务于作品审核、分发或推荐,优质歌手挖掘在社交、游戏等C端场景,可提供“开口跪挑战”等运营玩法。 懂AI又懂乐理,看图识谱技术上的又一次突破 随着深度学习方法的应用,OCR(图像文字识别 )近年得到了长足的进步,而OMR(图像乐谱识别)却始终处于研究应用的初级阶段。由于这个方向属于交叉学科,既要懂视觉算法又要懂乐理。目前市面上的商业或开源软件都不具备可用的准确率。 因此,网易云音乐音视频实验室采用基于端到端的算法识别路线,优化识别流程:1)拿到一个乐谱图片,检测图片中的曲谱位置坐标;2)提取曲谱区域,进行曲谱识别,识别出乐谱中的内容信息,如下图:
针对该乐谱识别模型,网易云音乐音频实验室也做了多方面的创新,大大提高了准确性。例如,将Transformer引入到乐谱识别任务中,通过该结构可以实现更大的感受野,有利于对长序列进行预测,提升识别准确率;同时,将乐谱的信息维度将乐谱符号分为:乐谱符号全局表征+乐谱符号局部表征+音符音高。这样的拆分方式更利于机器理解和学习。 值得注意的是,团队还精心设计了一套乐谱图片拍摄的方案。为了收集大量真实的数据,使用手机作为拍照工具,模仿最真实的拍照场景,对明、暗光场景的纸质乐谱进行拍照,以及对显示在显示屏上的乐谱进行拍照。 实验结果表示,网易云音乐的乐谱识别算法的准确性已经超过目前最好的端到端音乐谱识别方法,大幅降低错误率。下图中第一行为正确的乐谱识别结果,第二行为目前最好的复音乐谱识别方法的识别结果,第三行为本技术提出方案的识别结果,红框标记的为错误区域。
据介绍,该方法可以准确地将图片乐谱转换为midi、musicxml等格式,未来可用于音乐辅助教育、听歌搜谱等场景中,致力于在音乐欣赏、教育、创作等场景上,为音乐人、用户提供更好的服务。 |